
News
- 10/07/2023:
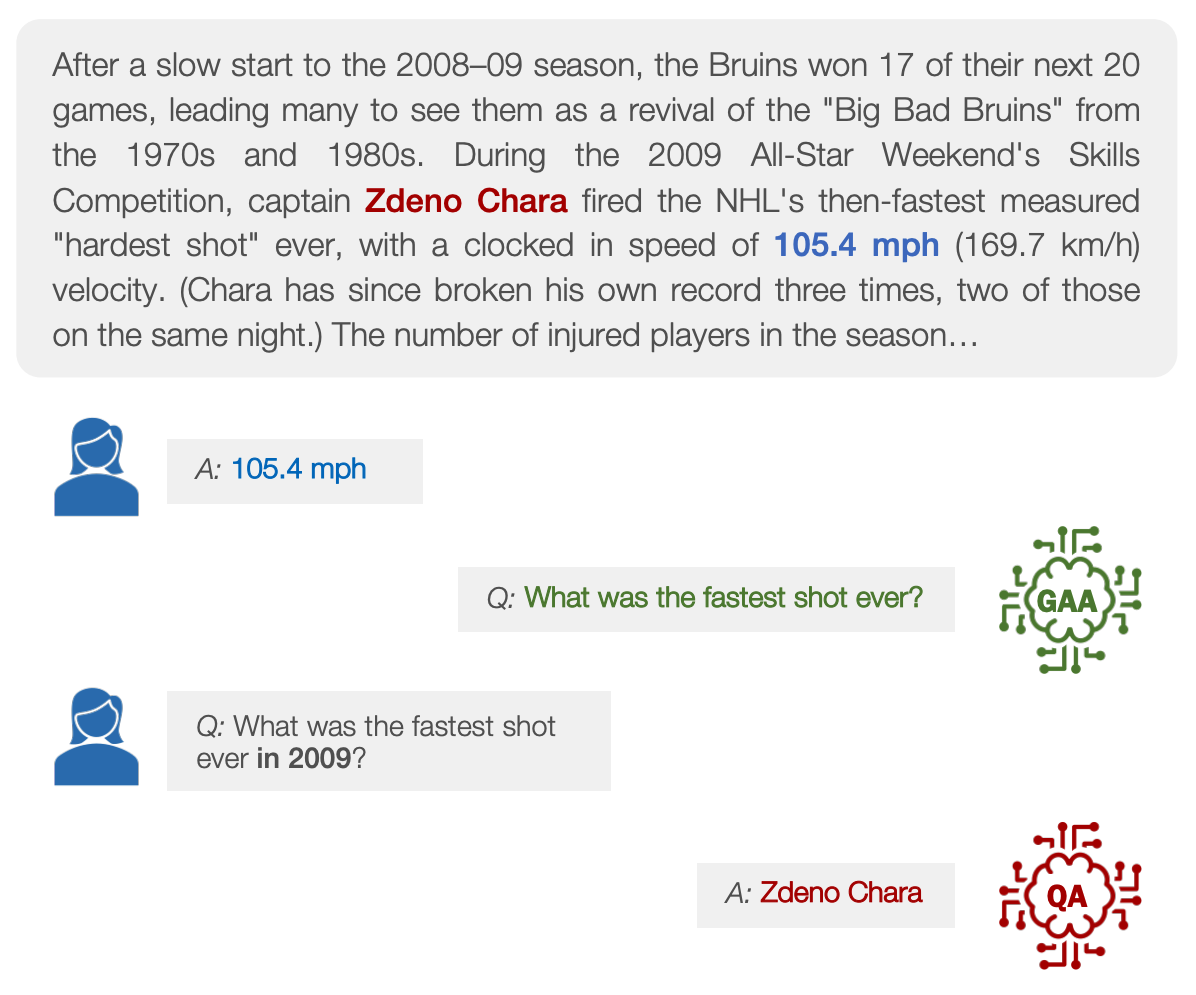
Our paper, What the DAAM: Interpreting Stable Diffusion Using Cross Attention, has won a Best Paper Award at ACL 2023! Congrats to authors Linqing and Pontus!
- 18/05/2022:
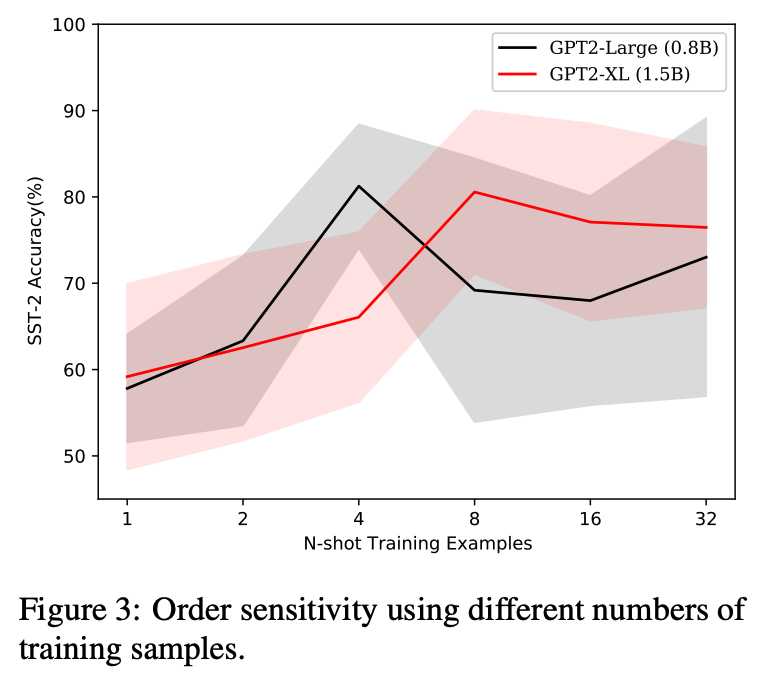
Our work Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity has been selected as an outstanding paper at ACL 2022!
- 26/03/2022:
The call for participation for the Shared Task at the DADC Workshop co-located with NAACL ‘22 in Seattle is now live! We have three fantastic tracks for you to participate in. Sign up here!
- 19/03/2022:
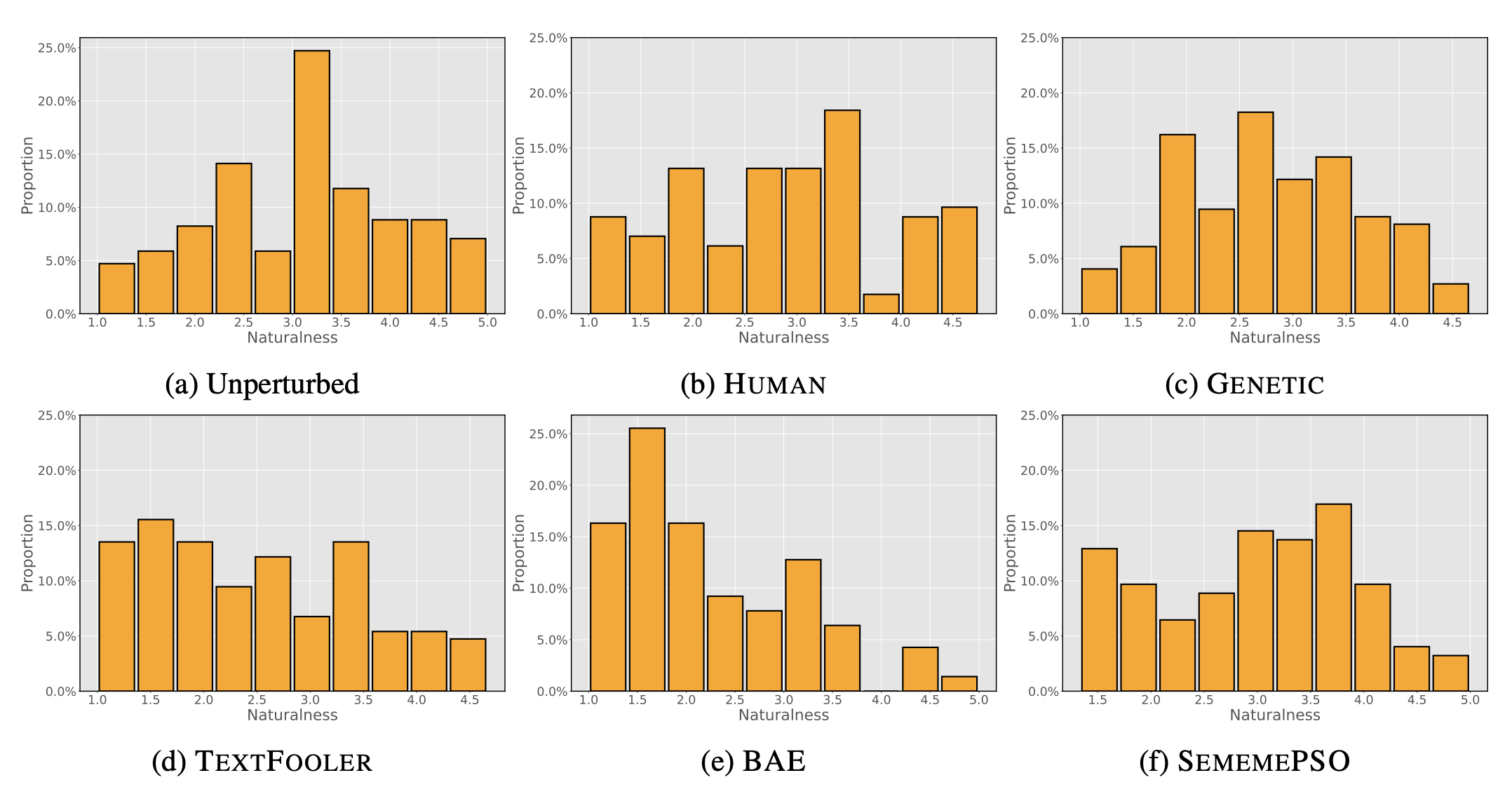
Additional resources from our work on Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation at EMNLP 2021 are now available! We are releasing a collection of synthetically-generated adversarial QA pairs and related resources as well as the models used to generate the questions.
- 28/02/2022:
Our AAAI 2022 tutorial, On Explainable AI: From Theory to Motivation, Industrial Applications, XAI Coding & Engineering Practices, was an outstanding success, with more than 600 attendees – check it out! Congratulations Pasquale and collaborators!
- 20/01/2022:
AdversarialQA is currently the 3rd most downloaded QA dataset on Huggingface 🤗 Datasets right after the benchmark SQuADv1.1 and SQuADv2!
- 04/01/2022:
Our proposal for the First Workshop on Dynamic Adversarial Data Collection has been accepted! See you at NAACL ‘22 in Seattle!
People

Pontus Stenetorp
Professor

Sebastian Riedel
Honorary Professor

Ehsan Shareghi
Associate Professor

Aldo Lipani
Associate Professor

Yao Lu
Assistant Professor

Atnafu Lambebo Tonja
Google DeepMind Academic Fellow

Xuanli He
Research Fellow

Anu Chowdhury
PhD Student

Bin Wu
PhD Student

Eduardo Sánchez
PhD Student

Hossein A. Rahmani
PhD Student

Jiayi Wang
PhD Student

Karen Hambardzumyan
PhD Student

Lovish Madaan
PhD Student

Shuofei Qiao
Visiting PhD Student

Sohee Yang
PhD student

Varsha Ramineni
PhD Student

Wiem Ben Rim
PhD Student

Xiao Fu
PhD Student

Adam Vawda
Research Assistant

Alice Winters
Group Administrator
Alumni

Max Bartolo
Now a Modelling Lead at Cohere

Pasquale Minervini
Now an Associate Professor at Edinburgh University

David Adelani
Now an assistant professor at McGill University and Mila

Luca Franceschi
Now a Research Scientist at Amazon

Oana-Maria Camburu
Now an assistant professor at Imperial College London

Tim Rocktäschel
Now a Professor at University College London

Linqing Liu
Now at Databricks Applied AI

Maximilian Mozes
Now a Member of Technical Staff at Cohere

Patrick Lewis
Now Director of Agentic AI at Cohere

Tom Crossland
Now a a Teaching Fellow at Imperial College London

Yue Feng
Now an assistant professor at University of Birmingham

Yuxiang Wu
Co-founder & CTO at Weco AI

Zhengyan Shi
Now a Senior Researcher at Microsoft Research

Matko Bošnjak
Now a Research Scientist at DeepMind

Alastair Roberts
Alastair’s interests lie in natural language processing & machine learning.

Johannes Welbl
Now a Research Scientist at DeepMind

Luke Hewitt
Now a PhD student at MIT

Gerasimos Lampouras
Now a research associate at University of Sheffield

Saku Sugawara
Now an Assistant Professor at National Institute of Informatics, Tokyo, Japan

Sonse Shimaoka
Now a master student at Tohoku University

Zhao Zhang
Now an Associate Professor at ICT, Chinese Academy of Sciences

Andreas Vlachos
Now a Professor at University of Cambridge

Guillaume Bouchard
Now CEO at CheckStep

Thomas Demeester
Now an associate professor at Ghent University

Jason Naradowsky
Now a research scientist at Preferred Networks (PFN)

Théo Trouillon
Now back to being a PhD student at Xerox Research Centre Europe

Marzieh Saeidi
Now a Research Scientist at Facebook

Isabelle Augenstein
Now an associate professor at University of Copenhagen

Naoya Inoue
Now an assistant professor at Tohoku University

Tim Dettmers
Now an assistant professor at Carnegie Mellon University

V. Ivan Sanchez
Now an NLP researcher at Lenovo

Andres Campero
Now back to being a PhD student at MIT

Takuma Yoneda
Now a Research Scientist at Google DeepMind

Georgios Spithourakis
Now a ML engineer at PolyAI
Publications
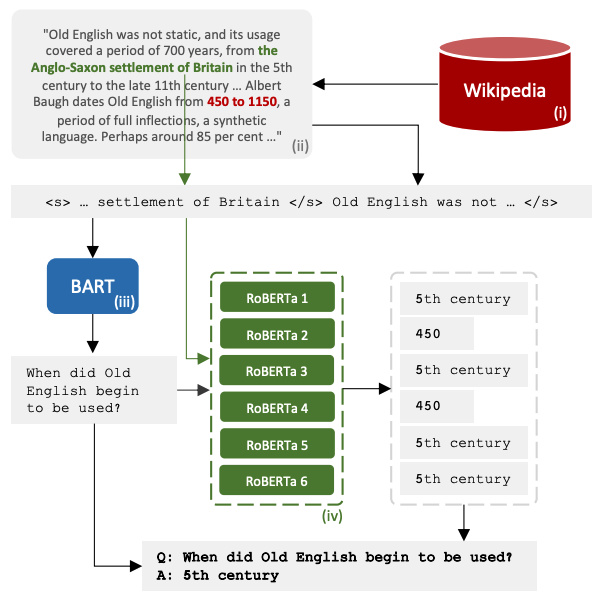
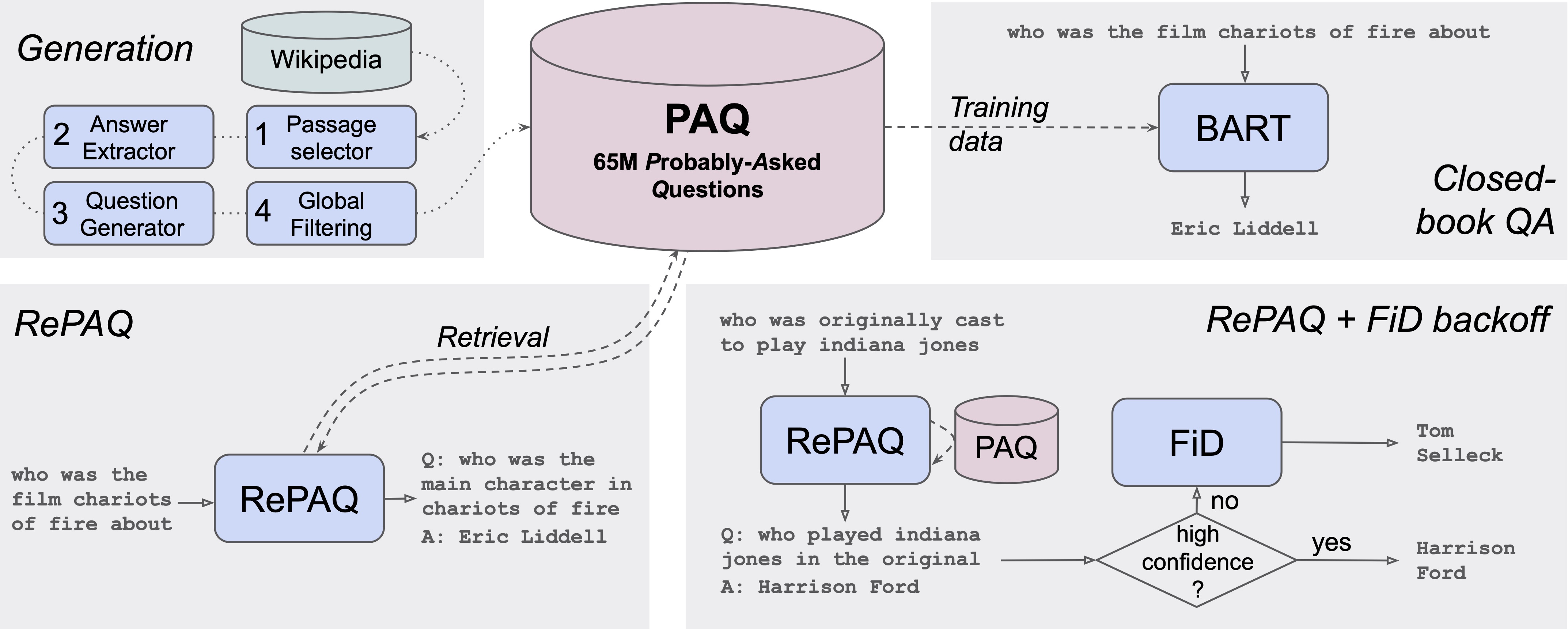
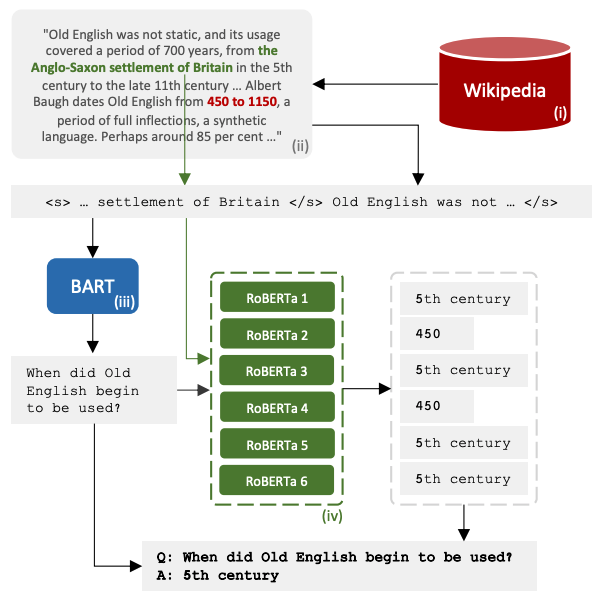
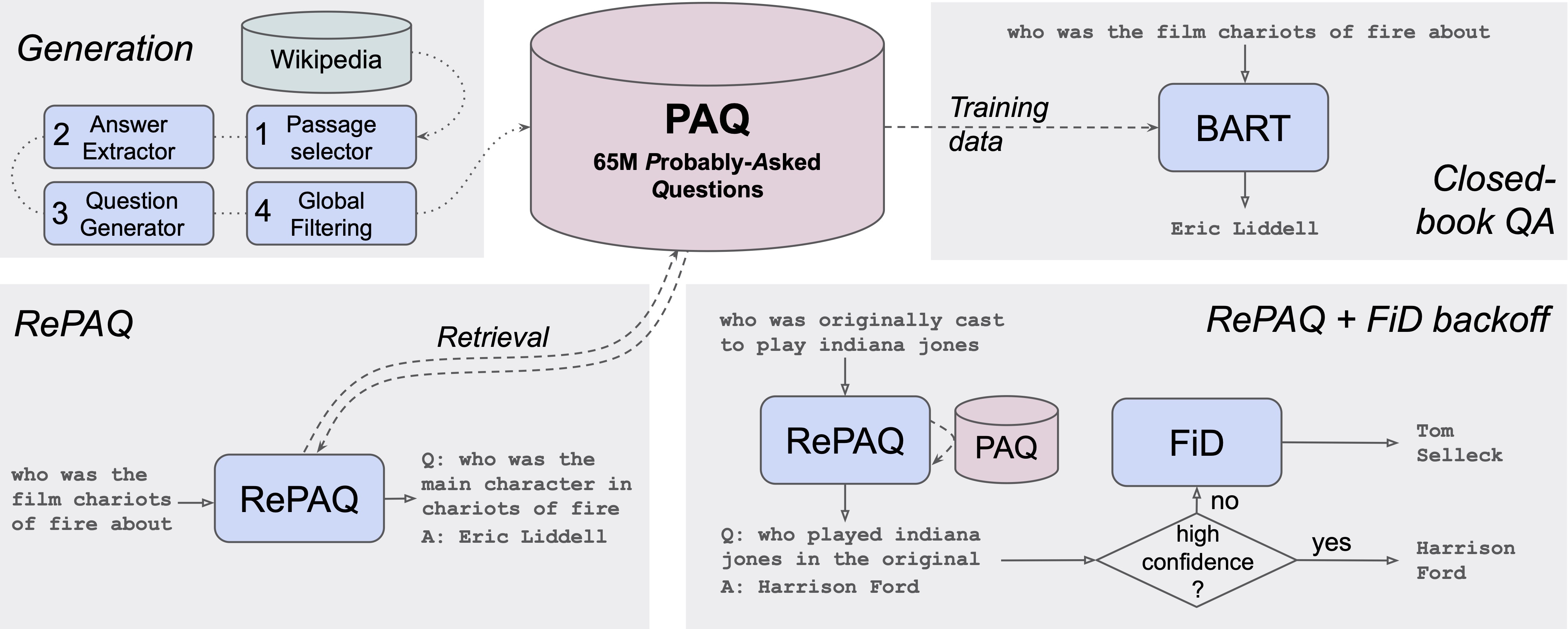
Datasets
SynQA
A synthetic dataset of 315k QA pairs on passages from SQuAD designed to help make QA models more robust to human adversaries. This resource is also available in HuggingFace datasets at https://huggingface.co/datasets/mbartolo/synQA.
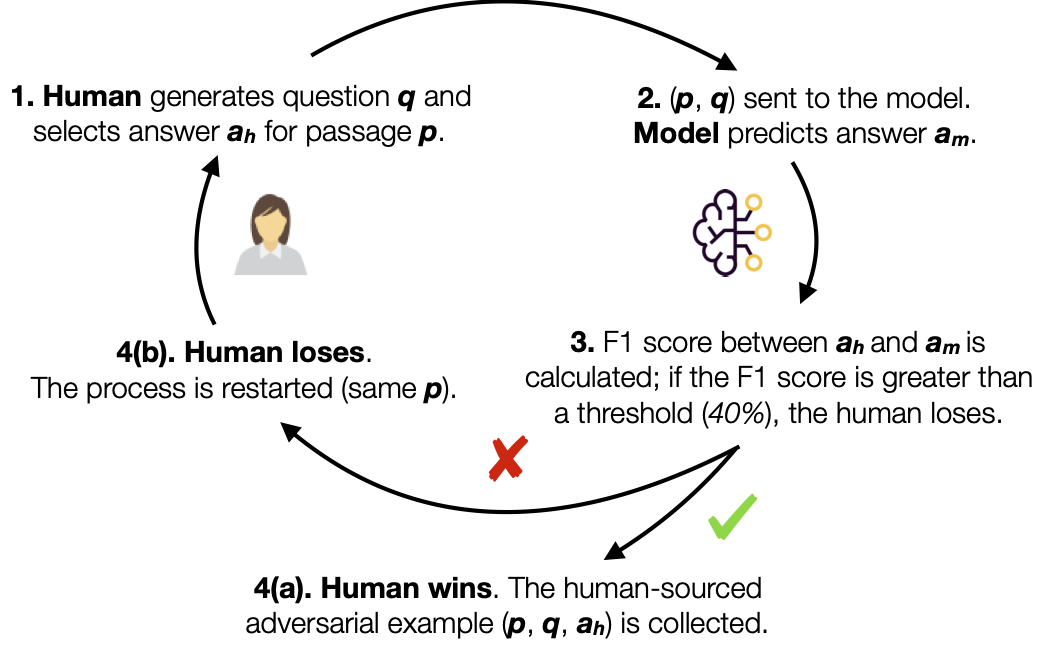
AdversarialQA (from Beat the AI)
A dataset of 36k challenging extractive QA pairs consisting of training, evaluation and test data collected using three different models-in-the-loop: BiDAF, BERT and RoBERTa.

KILT: a Benchmark for Knowledge Intensive Language Tasks
A resource for training, evaluating and analyzing NLP models on Knowledge Intensive Language Tasks. KILT has been built from 11 datasets representing 5 tasks.

MLQA
A multi-way aligned extractive QA evaluation benchmark MLQA contains QA instances in 7 languages, English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese.
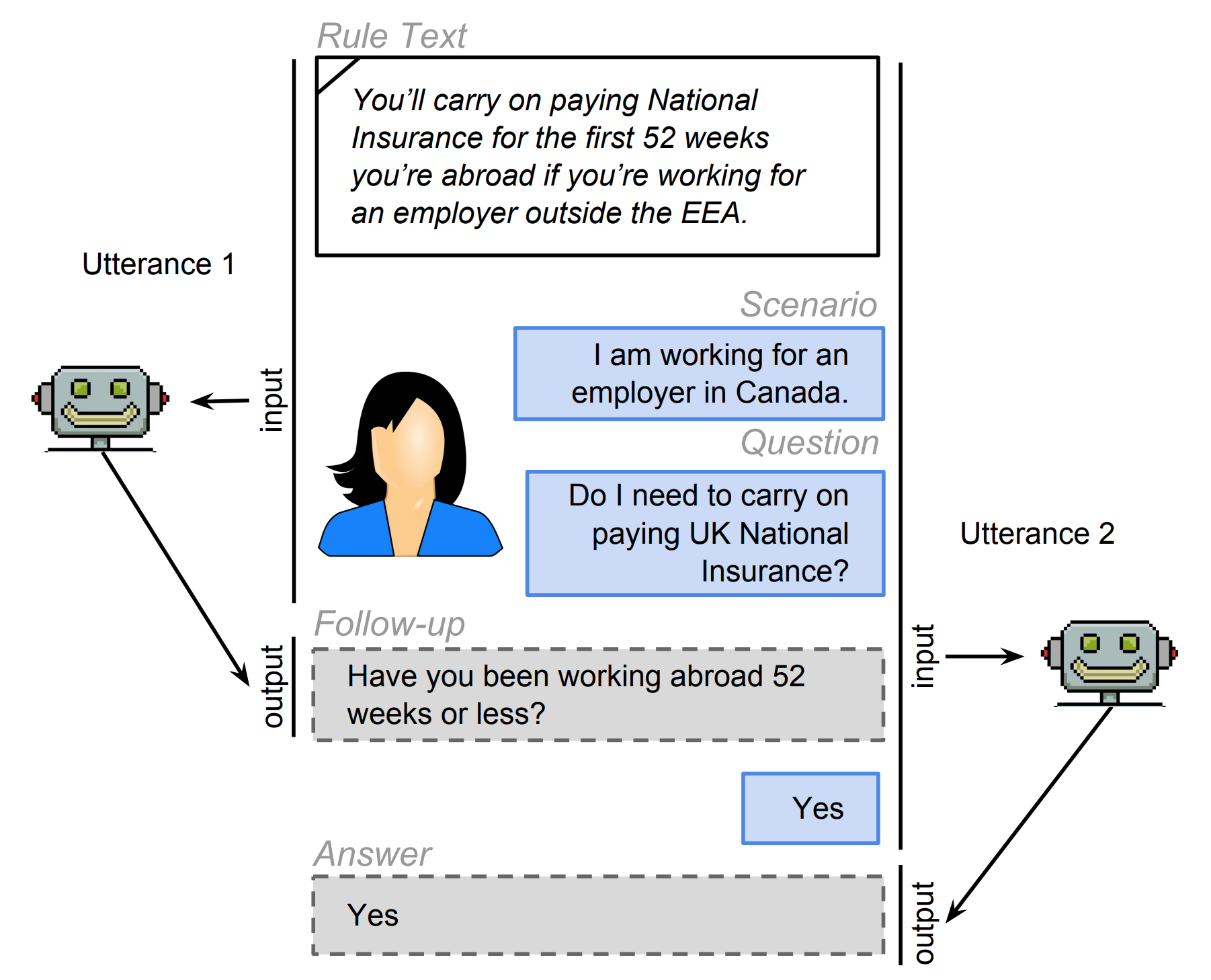
ShARC: Shaping Answers with Rules through Conversation
A collection of 32k task instances based on real-world rules and crowd-generated questions and scenarios requiring both the interpretation of rules and the application of background knowledge.

WikiHop & MedHop (QAngaroo)
Multi-hop question answering datasets from two different domains, designed to enabe models to combine disjoint pieces of textual evidence.